
但是随着DeepSeek R1等开源模型的出现,低成本私有化部署大模型成为可能,企业基于现成的框架微调模型,可以避免从零构建的巨额投入。
然而在大模型落地企业应用过程中,完成部署并不意味着开发工作到达了“终点”。企业数据爆炸式地增长和持续迭代,要求AI必须具备“终身学习”的能力。
一旦丧失这种能力,大模型会很快表现出能力的“天花板”,包括产生幻觉、缺乏对生成文本的可解释性、专业领域知识理解差,以及对最新知识的了解有限等等,无法真正地为企业解决问题。
而RAG(Retrieval-augmented Generation,检索增强生成)可以让大模型利用外部的知识库来增强生成能力,提高内容生成质量和可靠性,让企业内部积累的大量数据得到有效利用,唤醒企业沉睡的知识。
01. RAG:给大模型装上“外挂知识”
RAG的核心思想是通过外挂知识库的方式,给大模型提供更可靠的知识来抑制模型产生幻觉,通过定期迭代知识库,解决大模型知识更新慢和训练成本高的问题。
如果说传统大模型像闭卷考试的学生,回答问题时只能靠考前死记硬背的知识答题,一旦遇到超纲的题目,就会胡编乱造,也就是产生幻觉。那么结合RAG技术的大模型,就相当于开卷考试,允许学生随时上网查答案,翻书本和笔记。
RAG 就像给大模型装了个 “外挂知识库”,让它从 “死记硬背的书呆子” 变成 “能查资料的学霸”。
企业只需定期更新知识库(比如每周导入最新财报、政策文件),就能让 AI 始终输出准确、符合业务场景的回答,同时避免了重新训练模型的天价成本。
比如,某制造企业将产品设计文档、工艺流程规范、质量检测标准等数据整合到私有知识库中,利用 RAG 技术与 AI 大模型相结合,实现了智能客服、技术支持等功能。当客户咨询产品相关问题时,AI 系统能够快速从知识库中检索到准确的答案,提供专业、高效的服务。
02. RAG很好,但好的RAG不好开发
RAG虽然很好,但是企业在实际开发应用的场景中,自建知识检索系统绝非易事。
许多企业误以为部署私有化大模型就是 “买台服务器 + 装个软件”,却忽略了 RAG(检索增强生成)技术的复杂性。
澳大利亚吉朗应用人工智能研究所 Scott Barnett等人在论文《Seven Failure Points When Engineering a Retrieval Augmented Generation System》, 总结了RAG系统在工程实践中常见的7个失败点。
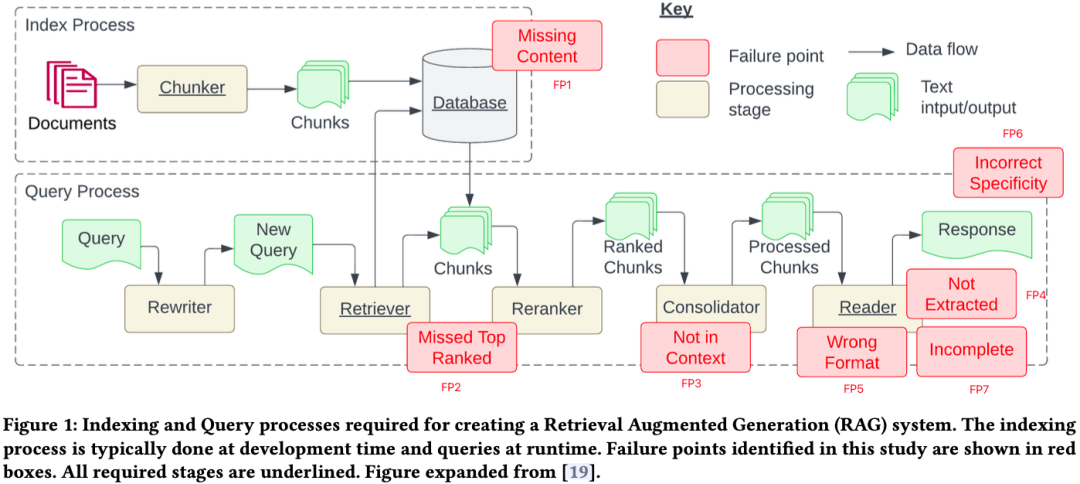
内容缺失(Missing Content)
就是说,有时候你问的问题,文档库里根本没有答案。理想情况下,RAG 系统应该回答“我不知道答案”。但实际上,如果系统被误导了,它可能会给你一个不相关的回答。
错过超出排名范围的文档(Missed the Top Ranked Documents)
问题的答案其实就在文档库里,但它的排名得分不够高,没能进入前 K 个文档,所以没被返回给用户。理论上,所有文档都会被排名,但实际操作中,为了提高效率,我们只能返回前 K 个文档。这个 K 值需要根据大模型的能力来折中选择。
不在上下文中(Not In Context)
系统从数据库里检索到了包含答案的文档,但在生成答案的时候,这些文档并没有被纳入上下文。这种情况通常发生在数据库返回了很多文档时,系统在整合这些文档时可能会出问题。
未提取(Not Extracted)
答案其实就在上下文中,但大模型没有提取出来。这通常是因为上下文里有太多噪声或者矛盾的信息。
错误的格式(Wrong Format)
问题要求以特定格式提取信息,例如表格或列表,然而大模型忽略了这个指示。
不正确的具体性(Incorrect Specificity)
尽管大模型正常回答了用户的提问,但不够具体或者过于具体,都不能满足用户的需求。这种情况通常发生在 RAG 系统设计者对某个问题有特定的期望结果时,比如老师对学生的要求。如果用户提问太笼统,也可能会出现这种问题。
不完整的回答(Incomplete Answers)
答案本身没有错误,但缺少了一些信息,尽管这些信息在上下文中是可以提取到的。
而英伟达生成式 AI 高级解决方案架构师Wenqi Glantz在文章《12 RAG Pain Points and Proposed Solutions》中又补充了5点。
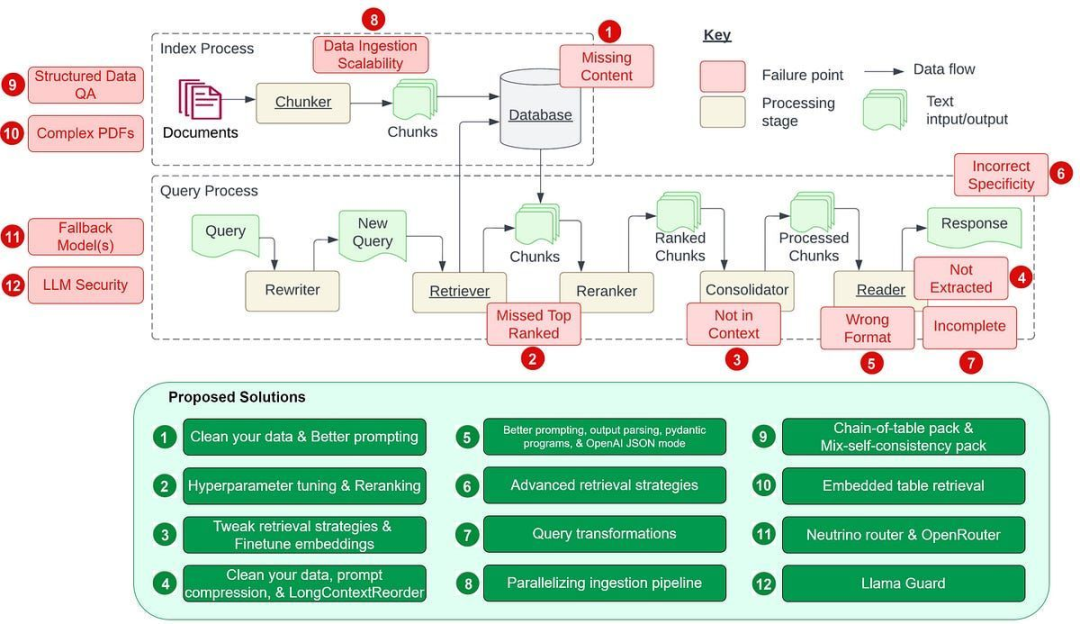
数据摄取的可扩展性(Data Ingestion Scalability)
当系统难以高效管理和处理大数据量的难题,可能导致出现性能瓶颈以及系统故障。这样的数据摄取可扩展性问题可能会导致摄取时间延长、系统过载、数据质量问题和可用性受限。
结构化数据问答(Structured Data QA)
当用户的问题比较复杂或比较模糊时,加上文本到 SQL 不灵活,大模型根据用户的问题准确检索出所需的结构化数据可能很困难。
从复杂 PDF 提取数据(Data Extraction from Complex PDFs)
复杂的PDF文档中可能包含有表格、图片等嵌入内容,在对这种文档进行问答时,传统的检索方法往往无法达到很好的效果。
备用模型(Fallback Model(s))
在使用单一大模型时,我们可能会担心模型遇到问题,比如遇到 OpenAI 模型的访问频率限制错误。这时候,我们需要一个或多个模型作为备用,以防主模型出现故障。
大模型的安全性(LLM Security)
如何有效地防止恶意输入、确保输出安全、保护敏感信息不被泄露等问题,都是每个AI架构师和工程师需要面对的重要挑战。
企业自建RAG除需攻克技术复杂性外,还面临三重成本黑洞:
- 开发成本:团队组建、硬件采购、模型调优、运维成本....
- 试错成本:开源方案适配、架构重构、数据治理....
- 机会成本:研发周期拉长,导致错失AI落地黄金窗口期....
然而,实际上这些仅仅是冰山一角,企业自建RAG挑战还远远不止这些。
相比于企业自己“造轮子”,专注于解决实际问题,快速响应市场需求可能是一个更好的选择。
3. 标普云BPai一体机:大模型+RAG,打造最智能的企业经营大脑
针对当前企业在构建RAG上普遍面临的难题,标普云BPai一体机提供了强大的RAG增强搜索能力,通过整合算力服务器、大模型、AI应用和企业私有知识库,预置了DeepSeek、BPai企业经营大模型等多个通用及行业模型,让企业能够轻松实现 “业务语言” 与 “AI 能力” 无缝对接,打造企业专属的智能大脑,构建最懂企业的AI智能体(数字员工)。
高效的文档解析与知识库构建
标普云BPai一体机适配PDF、TXT、DOCX等多类文档格式上传解析,可深度处理文档内容,通过强大数据清洗和灵活的知识分块,帮助企业建立高质量私域知识库,并支持复杂问题、大型数据集或跨多个文档查询。
更优的检索增强生成效果
标普云BPai一体机通过 RAG 技术,能敏捷抓取最新知识融入大模型,实现检索库的定期更新,从而确保生成的文本内容基于最新的信息,提升生成内容的准确性和效率,切实满足企业多样化的使用需求。
企业专属的AI智能体(数字员工)
标普云BPai一体机预装企业客服、办公助手、企业内部知识咨询等3大企业AI 智能体(数字员工),无需复杂配置,用户导入本地知识数据,即可快速启用。
除预装智能体外,企业还可以根据自由的业务场景构建专属的AI智能体(数字员工):
比如企业智能运营Agent(智能办公助手、智能HR、智能客服助手、智能销售助手)、金融行业Agent(智能录入助手、智能审核助手、智能风控助手、智能语音质检助手)、工业Agent(智能标签审核助手、智能质检助手、智能软件操作助手)、保险Agent(智能核保助手、智能保单录入助手、智能理赔助手、智能风控助手)等。
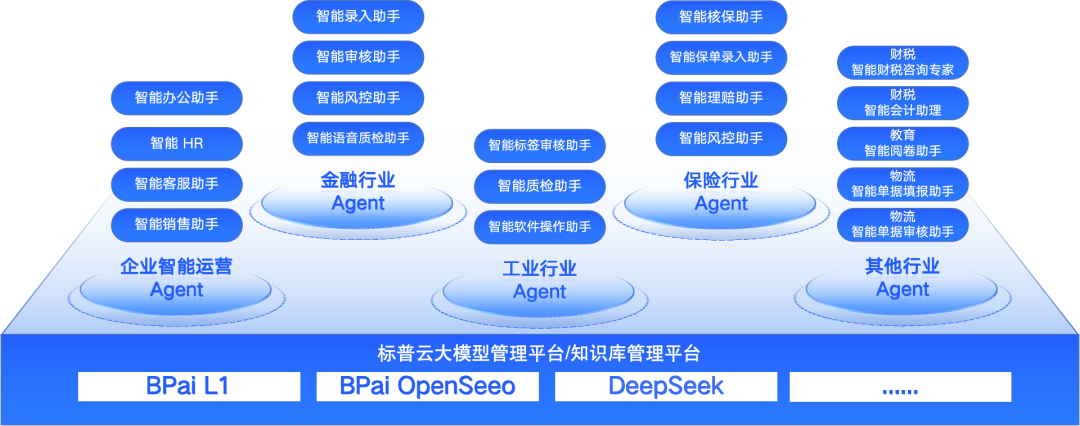
还有更多企业行业Agent,如财税行业的智能财税咨询专家、智能会计助理;教育行业的智能阅卷助手;物流行业的智能单据填报助手、智能单据审核助手等。
通过大模型私有化部署与 RAG 技术融合,BPai一体机让企业数据转化为可生长的智能资产,实现 "知识管理 - 智能体开发 - 场景落地" 的无缝衔接。未来,标普云将致力于让每个企业都能拥有专属的企业经营大脑,推动千行百业从数字化向智能化跃迁,共建人机协同的智慧未来。
如果你也想私有化部署DeepSeek等大模型,但是又苦于自建RAG烦恼,欢迎联系我们~